- ERP - Ethernet Ring Protection
- LAG - Link Aggregation Groups
La información de ambos protocolos es la misma que se expone en el JNCIS-ENT.
ERP - Ethernet Ring Protection
ERPS se define en el estándar ITU-T G.8032. Es un protocolo que provee estabilidad y un entorno libre de bucles. Es una solución para anillos ethernet que puede proporcionar un tiempo de respuesta por debajo de los 50ms. Se puede usar en sustitución del STP. El mínimo para montar un anillo son 3 nodos y, se recomienda no superar los 16 nodos.
 |
| ERPS no es soportado por todos los modelos de EX |
La
idea es que uno de los enlaces se use para proteger el anillo. Este
enlace es el RPL (Ring Protection Link). El que controla este enlace es
el RPL Owner y mientras están todos los demás enlaces levantados, el RPL
permancerá en estado de "blocking". Cuando falle uno, hará los cálculos
necesarios para habilitar el anillo. Solo habrá un RPL Owner por
anillo.
El
RPL Owner envía mensajes periódicos del tipo R-APS (Ring Automatic
Protection Switching) para notificar a los otros nodos el estado del
RPL. Escucha y envía mensajes. Sin embargo, cuando el fallo es en un
equipo normal, los propios equipos locales mandarán mensajes APS para
notificar a los demás la caída del enlace.
El Protocolo APS

APS necesita un canal dedicado para enviar y recibir los mensajes R-APS, que será una VLAN.
Usa
CFM (Connectivity Fault Management) para el formato de las tramas. Para
diferenciar los mensajes APS de otros mensajes tipo CFM, APS usa como
dirección de destino 01-19-A7-00-00-01, con un Upcode de 40 y el Flag en 0.

- Request/State: 4 bits. Valores: 0000 - no hay fallos; 1011 - señal de fallo
- Reserved 1: 4 bits. Valor: siempre 0000
- RPL Blocked: 1 bit. Solo el Owner puede ponerlo en este estado.
- Do not flush: 1 bit. Valores. 1 para no hacer flush; 0 para hacer un flush.
- Status Reserved: 6 bits. Valor: siempre 0000
- Node ID: 6 octetos. Dirección mac única
- Reserved 2: 24 octetos. Valor: todo a 0000

Cuando
el anillo está funcionando correctamente, todos los nodos están en
estado IDLE. Durante este estado es el Owner quien pone en estado de
blocking al RPL. El Owner envía periódicamente mensajes R-APS cada 5
segundos señalizando que no hay problemas en el anillo.
Cuando hay un fallo se lanza una "señal de fallo":

Switch 2 y 3:
- Esperan a que pase el intervalo de tiempo de espera (por defecto 0)
- Cambian de estado IDLE al estado de PROTECTION
- Bloquean los puertos que han fallado y limpia las tablas mac (flush)
- Envían 3 mensajes en los 10ms primeros seguidos por uno cada 5 segundos hasta que las condiciones de la caída se recuperan.
En el resto de los switches que participan:
- Cambian de estado IDLE al estado de PROTECTION
- Limpian las mac y paran de enviar mensajes R-APS
RPL Owner:
- Desbloquea el RPL
- Escucha los mensajes R-APS de los switches 2 y 3
 |
| Se desbloquea el RPL y volvemos a tener el anillo |
Cuando se recupera de un "fallo de enlace":
Cuando el enlace entre switch2 y 3 se recupera, empiezan a mandar R-APS (request/state=no request) para decir que el fallo no está ya presente y que no limpien la tabla de direcciones mac (do not flush=1). Mantienen los puertos en bloqueo hasta que llegan los R-APS hasta el RPL Owner.

Una vez que el RPL Owner recibe los mensajes R-APS:
- El Owner espera un tiempo de recuperación (5 minutos por defecto)
- Bloquea el RPL y envía R-APS (request/state=no request;RPLBlocked=1;Do not flush=0)
- Los demás switches desbloquean puertos y limpian sus tablas de direcciones mac
- Todos los switches cambian del estado de PROTECTION al estado de IDLE.

CONFIGURACIÓN DE ERPS
 |
| Opciones de configuración |
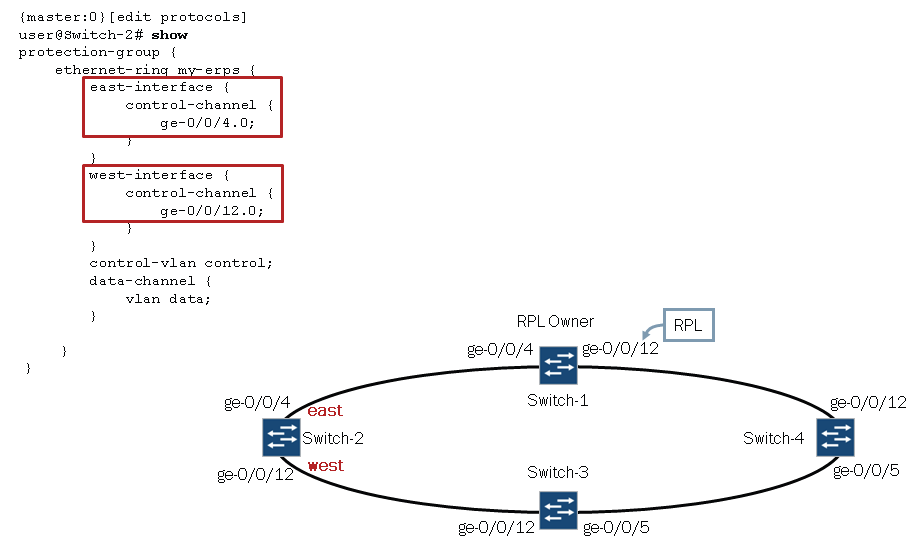
Siempre hay que configurar una interfaz ESTE y otra OESTE
Guard Interval:
deshabilitado por defecto. Configura intervalos de 10ms hasta los
2000ms. Se usa para prevenir la recepción de mensajes R-APS caducados,
descartando los mensajes que lleguen durante este tiempo. Cuando llega
un R-APS correcto, este intervalo se pone a 0.
Restore Interval: especifica el número de minutos que el nodo espera antes de procesar las PDU's de ERP

- Configurar las dos interfaces del switch 1
- Vlan de datos: 101
- Vlan de control: 100
- En modo trunk hay que especificar las vlans que pasan

- Configuramos el PROTECTION GROUP como Owner en el switch 1
 |
| Una interface ESTE y otra OESTE |
CONFIGURACIÓN DE UN NODO NORMAL

Para monitorizar:
 |
| show protection-group ethernet-ring |
 |
| Al tener el RPL bloqueado y el Originator en "yes", sabemos que es el Owner |
Para ver las interfaces que participan en el anillo:
 |
| Cuando el "admin state" está en "ready", el canal de control está habilitado para enviar R-APS |
Para ver los detalles del nodo local:

Para ver estadísticas del nodo:
 |
| Para limpiar estadísticas: clear protection-group ethernet-ring group-name X |

Cuando
se implementa LAGS se hace en conexiones P2P entre dos dispositivos.
Dependiendo del número de interfaces que participen, incrementará
proporicionalmente el ancho de banda del LAG y además aumenta también la
disponibilidad para transportar tráfico si se cae un interfaz.
Para crear un LAG hay que tener en cuenta que:
- La configuración del Duplex tiene que ser igual en ambos equipos
- Un máximo de 8 interfaces para formar un LAG
- Los miembros no tienen por qué estar conectados por puertos contiguos y pueden ser miembros de diferentes Virtual Chassis.
Consideraciones sobre el procesamiento del tráfico cuando hemos configurado un LAG:

- Todo tráfico generador por la RE que atraviese el LAG usará el miembro más bajo
- El algoritmo de balanceo de "tráfico IP" usa criterios de capa 2, 3 y 4. No se necesita configurar nada para habilitar el balanceo de carga.
- El algoritmo de balanceo de "tráfico NO IP" usa las direcciones mac de origen y destino
El protocolo que usa Junos es LACP - Link Aggregation Control Protocol (802.3ad). Se usa para unir dos o más interfaces físicas en una lógica, para interfaces Tagged (Troncal) o Untagged (de acceso).
El modo de los equipos puede ser activo o pasivo. Siempre tendrá que haber al menos uno activo para formarse. Al equipo local se le llama "actor" y al remoto se le llama "partner". Se intercambian siempre PDU's a través de todos los enlaces físicos para asegurarse de que están funcionando todos los enlaces correctamente.
Se puede hacer un "Multichassis Link Aggregation". Esto habilita la formación de unh LAG entre interfaces de diferentes dispositivos. Soporta multihoming y redundancia a nivel de nodo.
El dispositivo MC-LAG usa ICCP (Inter-chassis Control Protocol) para intercambiar info con otros dispositivos MC_LAG.

El Switch-1 es un cliente MC-LAG que tiene 4 enlaces. Este cliente no necesita saber que es un MC-LAG, es decir, no le importa si los enlaces no pertenecen al mismo equipo. En el otro lado los switches 2 y 3 se coordinan para el envío del tráfico.
Corre sin STP y ofrece una capa 2 libre de bucles.
Para crear un LAG:
#set chassis aggregated-device ethernet device-count X - siendo X el número de LAGS que creamos
 |
| Cuando creamos LAGS empieza la númeración con ae0 |
Y después configuramos las interfaces ethernet:
 |
| Configuración de un Aggregated de capa 2 |
Por defecto, los equipos mandan paquetes LACP cada segundo. Este intervalo se puede modificar:
#set interfaces ae0 aggregated-ether-options lacp periodic fast/slow
Si configuramos fast el intervalo es cada segundo. Slow es cada 30. Se puede incluso configurar a diferente intervalo cada equipo.
Para monitorizar LACP:
 |
| También podemos usar: show lacp interfaces o show interfaces lacp statistics |
Para monitorizar a través de un traceoption, tenemos que hacerlo desde "protocols lacp".

No hay comentarios:
Publicar un comentario